#pyspark certification
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
What is PySpark? A Beginner’s Guide
Introduction
The digital era gives rise to continuous expansion in data production activities. Organizations and businesses need processing systems with enhanced capabilities to process large data amounts efficiently. Large datasets receive poor scalability together with slow processing speed and limited adaptability from conventional data processing tools. PySpark functions as the data processing solution that brings transformation to operations.
The Python Application Programming Interface called PySpark serves as the distributed computing framework of Apache Spark for fast processing of large data volumes. The platform offers a pleasant interface for users to operate analytics on big data together with real-time search and machine learning operations. Data engineering professionals along with analysts and scientists prefer PySpark because the platform combines Python's flexibility with Apache Spark's processing functions.
The guide introduces the essential aspects of PySpark while discussing its fundamental elements as well as explaining operational guidelines and hands-on usage. The article illustrates the operation of PySpark through concrete examples and predicted outputs to help viewers understand its functionality better.
What is PySpark?
PySpark is an interface that allows users to work with Apache Spark using Python. Apache Spark is a distributed computing framework that processes large datasets in parallel across multiple machines, making it extremely efficient for handling big data. PySpark enables users to leverage Spark’s capabilities while using Python’s simple and intuitive syntax.
There are several reasons why PySpark is widely used in the industry. First, it is highly scalable, meaning it can handle massive amounts of data efficiently by distributing the workload across multiple nodes in a cluster. Second, it is incredibly fast, as it performs in-memory computation, making it significantly faster than traditional Hadoop-based systems. Third, PySpark supports Python libraries such as Pandas, NumPy, and Scikit-learn, making it an excellent choice for machine learning and data analysis. Additionally, it is flexible, as it can run on Hadoop, Kubernetes, cloud platforms, or even as a standalone cluster.
Core Components of PySpark
PySpark consists of several core components that provide different functionalities for working with big data:
RDD (Resilient Distributed Dataset) – The fundamental unit of PySpark that enables distributed data processing. It is fault-tolerant and can be partitioned across multiple nodes for parallel execution.
DataFrame API – A more optimized and user-friendly way to work with structured data, similar to Pandas DataFrames.
Spark SQL – Allows users to query structured data using SQL syntax, making data analysis more intuitive.
Spark MLlib – A machine learning library that provides various ML algorithms for large-scale data processing.
Spark Streaming �� Enables real-time data processing from sources like Kafka, Flume, and socket streams.
How PySpark Works
1. Creating a Spark Session
To interact with Spark, you need to start a Spark session.

Output:

2. Loading Data in PySpark
PySpark can read data from multiple formats, such as CSV, JSON, and Parquet.

Expected Output (Sample Data from CSV):

3. Performing Transformations
PySpark supports various transformations, such as filtering, grouping, and aggregating data. Here’s an example of filtering data based on a condition.

Output:

4. Running SQL Queries in PySpark
PySpark provides Spark SQL, which allows you to run SQL-like queries on DataFrames.

Output:
5. Creating a DataFrame Manually
You can also create a PySpark DataFrame manually using Python lists.

Output:

Use Cases of PySpark
PySpark is widely used in various domains due to its scalability and speed. Some of the most common applications include:
Big Data Analytics – Used in finance, healthcare, and e-commerce for analyzing massive datasets.
ETL Pipelines – Cleans and processes raw data before storing it in a data warehouse.
Machine Learning at Scale – Uses MLlib for training and deploying machine learning models on large datasets.
Real-Time Data Processing – Used in log monitoring, fraud detection, and predictive analytics.
Recommendation Systems – Helps platforms like Netflix and Amazon offer personalized recommendations to users.
Advantages of PySpark
There are several reasons why PySpark is a preferred tool for big data processing. First, it is easy to learn, as it uses Python’s simple and intuitive syntax. Second, it processes data faster due to its in-memory computation. Third, PySpark is fault-tolerant, meaning it can automatically recover from failures. Lastly, it is interoperable and can work with multiple big data platforms, cloud services, and databases.
Getting Started with PySpark
Installing PySpark
You can install PySpark using pip with the following command:

To use PySpark in a Jupyter Notebook, install Jupyter as well:

To start PySpark in a Jupyter Notebook, create a Spark session:

Conclusion
PySpark is an incredibly powerful tool for handling big data analytics, machine learning, and real-time processing. It offers scalability, speed, and flexibility, making it a top choice for data engineers and data scientists. Whether you're working with structured data, large-scale machine learning models, or real-time data streams, PySpark provides an efficient solution.
With its integration with Python libraries and support for distributed computing, PySpark is widely used in modern big data applications. If you’re looking to process massive datasets efficiently, learning PySpark is a great step forward.
youtube
#pyspark training#pyspark coutse#apache spark training#apahe spark certification#spark course#learn apache spark#apache spark course#pyspark certification#hadoop spark certification .#Youtube
0 notes
Text
From Beginner to Pro: The Best PySpark Courses Online from ScholarNest Technologies

Are you ready to embark on a journey from a PySpark novice to a seasoned pro? Look no further! ScholarNest Technologies brings you a comprehensive array of PySpark courses designed to cater to every skill level. Let's delve into the key aspects that make these courses stand out:
1. What is PySpark?
Gain a fundamental understanding of PySpark, the powerful Python library for Apache Spark. Uncover the architecture and explore its diverse applications in the world of big data.
2. Learning PySpark by Example:
Experience is the best teacher! Our courses focus on hands-on examples, allowing you to apply your theoretical knowledge to real-world scenarios. Learn by doing and enhance your problem-solving skills.
3. PySpark Certification:
Elevate your career with our PySpark certification programs. Validate your expertise and showcase your proficiency in handling big data tasks using PySpark.
4. Structured Learning Paths:
Whether you're a beginner or seeking advanced concepts, our courses offer structured learning paths. Progress at your own pace, mastering each skill before moving on to the next level.
5. Specialization in Big Data Engineering:
Our certification course on big data engineering with PySpark provides in-depth insights into the intricacies of handling vast datasets. Acquire the skills needed for a successful career in big data.
6. Integration with Databricks:
Explore the integration of PySpark with Databricks, a cloud-based big data platform. Understand how these technologies synergize to provide scalable and efficient solutions.
7. Expert Instruction:
Learn from the best! Our courses are crafted by top-rated data science instructors, ensuring that you receive expert guidance throughout your learning journey.
8. Online Convenience:
Enroll in our online PySpark courses and access a wealth of knowledge from the comfort of your home. Flexible schedules and convenient online platforms make learning a breeze.
Whether you're a data science enthusiast, a budding analyst, or an experienced professional looking to upskill, ScholarNest's PySpark courses offer a pathway to success. Master the skills, earn certifications, and unlock new opportunities in the world of big data engineering!
#big data#data engineering#data engineering certification#data engineering course#databricks data engineer certification#pyspark course#databricks courses online#best pyspark course online#pyspark online course#databricks learning#data engineering courses in bangalore#data engineering courses in india#azure databricks learning#pyspark training course#pyspark certification course
1 note
·
View note
Text
Senior Data Engineer
Job title: Senior Data Engineer Company: Yodlee Job description: : Python, PySpark, ANSI SQL, Python ML libraries Frameworks/Platform: Spark, Snowflake, Airflow, Hadoop , Kafka Cloud… with remote teams AWS Solutions Architect / Developer / Data Analytics Specialty certifications, Professional certification… Expected salary: Location: Thiruvananthapuram, Kerala Job date: Thu, 22 May 2025 03:39:21…
0 notes
Text
Best Azure Data Engineer Course In Ameerpet | Azure Data
Understanding Delta Lake in Databricks
Introduction
Delta Lake, an open-source storage layer developed by Databricks, is designed to address these challenges. It enhances Apache Spark's capabilities by providing ACID transactions, schema enforcement, and time travel, making data lakes more reliable and efficient. In modern data engineering, managing large volumes of data efficiently while ensuring reliability and performance is a key challenge.

What is Delta Lake?
Delta Lake is an optimized storage layer built on Apache Parquet that brings the reliability of a data warehouse to big data processing. It eliminates the limitations of traditional data lakes by adding ACID transactions, scalable metadata handling, and schema evolution. Delta Lake integrates seamlessly with Azure Databricks, Apache Spark, and other cloud-based data solutions, making it a preferred choice for modern data engineering pipelines. Microsoft Azure Data Engineer
Key Features of Delta Lake
1. ACID Transactions
One of the biggest challenges in traditional data lakes is data inconsistency due to concurrent read/write operations. Delta Lake supports ACID (Atomicity, Consistency, Isolation, Durability) transactions, ensuring reliable data updates without corruption. It uses Optimistic Concurrency Control (OCC) to handle multiple transactions simultaneously.
2. Schema Evolution and Enforcement
Delta Lake enforces schema validation to prevent accidental data corruption. If a schema mismatch occurs, Delta Lake will reject the data, ensuring consistency. Additionally, it supports schema evolution, allowing modifications without affecting existing data.
3. Time Travel and Data Versioning
Delta Lake maintains historical versions of data using log-based versioning. This allows users to perform time travel queries, enabling them to revert to previous states of data. This is particularly useful for auditing, rollback, and debugging purposes. Azure Data Engineer Course
4. Scalable Metadata Handling
Traditional data lakes struggle with metadata scalability, especially when handling billions of files. Delta Lake optimizes metadata storage and retrieval, making queries faster and more efficient.
5. Performance Optimizations (Data Skipping and Caching)
Delta Lake improves query performance through data skipping and caching mechanisms. Data skipping allows queries to read only relevant data instead of scanning the entire dataset, reducing processing time. Caching improves speed by storing frequently accessed data in memory.
6. Unified Batch and Streaming Processing
Delta Lake enables seamless integration of batch and real-time streaming workloads. Structured Streaming in Spark can write and read from Delta tables in real-time, ensuring low-latency updates and enabling use cases such as fraud detection and log analytics.
How Delta Lake Works in Databricks?
Delta Lake is tightly integrated with Azure Databricks and Apache Spark, making it easy to use within data pipelines. Below is a basic workflow of how Delta Lake operates: Azure Data Engineering Certification
Data Ingestion: Data is ingested into Delta tables from multiple sources (Kafka, Event Hubs, Blob Storage, etc.).
Data Processing: Spark SQL and PySpark process the data, applying transformations and aggregations.
Data Storage: Processed data is stored in Delta format with ACID compliance.
Query and Analysis: Users can query Delta tables using SQL or Spark.
Version Control & Time Travel: Previous data versions are accessible for rollback and auditing.
Use Cases of Delta Lake
ETL Pipelines: Ensures data reliability with schema validation and ACID transactions.
Machine Learning: Maintains clean and structured historical data for training ML models. Azure Data Engineer Training
Real-time Analytics: Supports streaming data processing for real-time insights.
Data Governance & Compliance: Enables auditing and rollback for regulatory requirements.
Conclusion
Delta Lake in Databricks bridges the gap between traditional data lakes and modern data warehousing solutions by providing reliability, scalability, and performance improvements. With ACID transactions, schema enforcement, time travel, and optimized query performance, Delta Lake is a powerful tool for building efficient and resilient data pipelines. Its seamless integration with Azure Databricks and Apache Spark makes it a preferred choice for data engineers aiming to create high-performance and scalable data architectures.
Trending Courses: Artificial Intelligence, Azure AI Engineer, Informatica Cloud IICS/IDMC (CAI, CDI),
Visualpath stands out as the best online software training institute in Hyderabad.
For More Information about the Azure Data Engineer Online Training
Contact Call/WhatsApp: +91-7032290546
Visit: https://www.visualpath.in/online-azure-data-engineer-course.html
#Azure Data Engineer Course#Azure Data Engineering Certification#Azure Data Engineer Training In Hyderabad#Azure Data Engineer Training#Azure Data Engineer Training Online#Azure Data Engineer Course Online#Azure Data Engineer Online Training#Microsoft Azure Data Engineer#Azure Data Engineer Course In Bangalore#Azure Data Engineer Course In Chennai#Azure Data Engineer Training In Bangalore#Azure Data Engineer Course In Ameerpet
0 notes
Text
Exploring Advanced Python Projects for Experienced Developers
For seasoned Python developers, continuously challenging oneself with complex projects is crucial for growth and skill enhancement. Here are some advanced Python project ideas that can significantly boost your expertise and broaden your programming horizons. Considering the kind support of Learn Python Course in Pune, Whatever your level of experience or reason for switching from another programming language, learning Python gets much more fun.

1. Machine Learning Innovations
Recommendation Engines
Dive into building a recommendation system using collaborative filtering or content-based filtering. This can be applied to various domains like movie suggestions, product recommendations, or even personalized content curation.
Advanced Natural Language Processing (NLP)
Engage in projects involving sentiment analysis, text summarization, or language translation using libraries such as NLTK, SpaCy, or TensorFlow. These projects will deepen your understanding of NLP and its applications.
Predictive Analytics
Develop predictive models using scikit-learn or TensorFlow to forecast stock prices, weather patterns, or sports results. These projects can help you master the art of predictive analytics and data handling.
2. Web Development Mastery with Django or Flask
Comprehensive E-commerce Platforms
Design and implement a robust e-commerce website featuring user authentication, product listings, shopping cart functionality, and payment processing. This will provide you with invaluable experience in web development and management.
Social Networking Applications
Create a social media platform complete with user profiles, posts, comments, and likes. Incorporate real-time updates using WebSockets to enhance user interaction and engagement.
3. Data Science and Analytical Projects
Big Data Handling
Utilize PySpark or Dask to manage and analyze large datasets. Potential projects include processing log files, analyzing social media data, or performing large-scale data aggregation to draw meaningful insights.
Interactive Data Visualization
Develop interactive dashboards using Plotly Dash or Bokeh to visualize complex datasets. These could include financial data, demographic information, or scientific research, providing insightful and engaging visual representations.
4. Automation and Scripting Challenges
Advanced Web Scraping
Create sophisticated web scrapers using BeautifulSoup, Scrapy, or Selenium to extract data from complex websites. Projects could include a price tracker, job aggregator, or research data collection tool.
Workflow Automation
Design scripts to automate repetitive tasks like file organization, email automation, or system monitoring and reporting. This can significantly enhance productivity and efficiency. Enrolling in the Best Python Certification Online can help people realise Python’s full potential and gain a deeper understanding of its complexities.

5. Blockchain and Cryptographic Projects
Blockchain Fundamentals
Implement a basic blockchain and simulate transactions, mining, and peer-to-peer networking. Explore creating smart contracts using Ethereum and Solidity to grasp the essentials of blockchain technology.
Cryptographic Systems
Develop and implement cryptographic algorithms like RSA, AES, or hashing techniques. Create secure messaging applications or file encryption tools to delve into cybersecurity.
6. Game Development Ventures
Game AI Development
Develop AI that can play classic games like Chess, Go, or Poker using algorithms such as Minimax, Alpha-Beta Pruning, or Monte Carlo Tree Search. This project will challenge your strategic thinking and AI programming skills.
3D Game Creation
Use a game engine like Pygame or Godot to build a 3D game. Integrate complex physics, graphics, and AI behaviors to create a rich and immersive gaming experience.
7. Internet of Things (IoT) Projects
Smart Home Automation
Construct an IoT-based home automation system using Raspberry Pi or Arduino. Integrate sensors and actuators, and create a web or mobile interface to control home appliances, enhancing convenience and efficiency.
Health Monitoring Systems
Develop a health monitoring system that collects data from wearable devices, processes it, and provides health insights and alerts. This project can have a significant impact on health and wellness.
8. Cybersecurity Development
Penetration Testing Tools
Create tools for network scanning, vulnerability assessment, or exploit development. Projects could include building a custom port scanner, brute-force attack tool, or network traffic analyzer.
Intrusion Detection Systems
Develop an intrusion detection system using machine learning to analyze network traffic and detect suspicious activities or anomalies. This will help you understand and implement advanced network security measures.
Conclusion
Engaging in advanced Python projects can push the boundaries of your programming abilities and introduce you to new technological domains. Each project offers an opportunity to deepen your understanding of complex concepts, experiment with new libraries and frameworks, and build a robust portfolio showcasing your skills. Whether you focus on machine learning, web development, data science, or cybersecurity, these projects provide valuable experience and pave the way for new career opportunities.
#python course#python training#python#technology#tech#python programming#python online training#python online course#python online classes
0 notes
Text

Ignite your passion for big data at iconGen IT Solutions with our pySpark Certification course. Explore the intersection of ambition and opportunity in the realm where big data thrives!
0 notes
Text
Pyspark Training
0 notes
Text
Transform Your Team into Data Engineering Pros with ScholarNest Technologies

In the fast-evolving landscape of data engineering, the ability to transform your team into proficient professionals is a strategic imperative. ScholarNest Technologies stands at the forefront of this transformation, offering comprehensive programs that equip individuals with the skills and certifications necessary to excel in the dynamic field of data engineering. Let's delve into the world of data engineering excellence and understand how ScholarNest is shaping the data engineers of tomorrow.
Empowering Through Education: The Essence of Data Engineering
Data engineering is the backbone of current data-driven enterprises. It involves the collection, processing, and storage of data in a way that facilitates effective analysis and insights. ScholarNest Technologies recognizes the pivotal role data engineering plays in today's technological landscape and has curated a range of courses and certifications to empower individuals in mastering this discipline.
Comprehensive Courses and Certifications: ScholarNest's Commitment to Excellence
1. Data Engineering Courses: ScholarNest offers comprehensive data engineering courses designed to provide a deep understanding of the principles, tools, and technologies essential for effective data processing. These courses cover a spectrum of topics, including data modeling, ETL (Extract, Transform, Load) processes, and database management.
2. Pyspark Mastery: Pyspark, a powerful data processing library for Python, is a key component of modern data engineering. ScholarNest's Pyspark courses, including options for beginners and full courses, ensure participants acquire proficiency in leveraging this tool for scalable and efficient data processing.
3. Databricks Learning: Databricks, with its unified analytics platform, is integral to modern data engineering workflows. ScholarNest provides specialized courses on Databricks learning, enabling individuals to harness the full potential of this platform for advanced analytics and data science.
4. Azure Databricks Training: Recognizing the industry shift towards cloud-based solutions, ScholarNest offers courses focused on Azure Databricks. This training equips participants with the skills to leverage Databricks in the Azure cloud environment, ensuring they are well-versed in cutting-edge technologies.
From Novice to Expert: ScholarNest's Approach to Learning
Whether you're a novice looking to learn the fundamentals or an experienced professional seeking advanced certifications, ScholarNest caters to diverse learning needs. Courses such as "Learn Databricks from Scratch" and "Machine Learning with Pyspark" provide a structured pathway for individuals at different stages of their data engineering journey.
Hands-On Learning and Certification: ScholarNest places a strong emphasis on hands-on learning. Courses include practical exercises, real-world projects, and assessments to ensure that participants not only grasp theoretical concepts but also gain practical proficiency. Additionally, certifications such as the Databricks Data Engineer Certification validate the skills acquired during the training.
The ScholarNest Advantage: Shaping Data Engineering Professionals
ScholarNest Technologies goes beyond traditional education paradigms, offering a transformative learning experience that prepares individuals for the challenges and opportunities in the world of data engineering. By providing access to the best Pyspark and Databricks courses online, ScholarNest is committed to fostering a community of skilled data engineering professionals who will drive innovation and excellence in the ever-evolving data landscape. Join ScholarNest on the journey to unlock the full potential of your team in the realm of data engineering.
#big data#big data consulting#data engineering#data engineering course#data engineering certification#databricks data engineer certification#pyspark course#databricks courses online#best pyspark course online#best pyspark course#pyspark online course#databricks learning#data engineering courses in bangalore#data engineering courses in india#azure databricks learning#pyspark training course
1 note
·
View note
Text
Mastering PySpark: A Comprehensive Certification Course and Effective Training Methods
Are you eager to delve into the world of big data analytics and data processing? Look no further than PySpark, a powerful tool for efficiently handling large-scale data. In this article, we will explore the PySpark certification course and its training methods, providing you with the essential knowledge to master this transformative technology.
Understanding PySpark: Unveiling the Power of Big Data
PySpark is a Python library for Apache Spark, an open-source, distributed computing system designed for big data processing and analysis. It enables seamless integration with Python, allowing developers to leverage the vast capabilities of Spark using familiar Python programming paradigms. PySpark empowers data scientists and analysts to process vast amounts of data efficiently, making it an invaluable tool in today's data-driven landscape.
The PySpark Certification Course: A Pathway to Expertise
Enrolling in a PySpark certification course can be a game-changer for anyone looking to enhance their skills in big data analytics. These courses are meticulously designed to provide a comprehensive understanding of PySpark, covering its core concepts, advanced features, and practical applications. The curriculum typically includes:
Introduction to PySpark: Understanding the basics of PySpark, its architecture, and key components.
Data Processing with PySpark: Learning how to process and manipulate data using PySpark's powerful capabilities.
Machine Learning with PySpark: Exploring how PySpark facilitates machine learning tasks, allowing for predictive modeling and analysis.
Real-world Applications and Case Studies: Gaining hands-on experience through real-world projects and case studies.
Training Methods: Tailored for Success
The training methods employed in PySpark certification courses are designed to maximize learning and ensure participants grasp the concepts effectively. These methods include:
Interactive Lectures: Engaging lectures delivered by experienced instructors to explain complex concepts in an easily digestible manner.
Hands-on Labs and Projects: Practical exercises and projects to apply the learned knowledge in real-world scenarios, reinforcing understanding.
Collaborative Learning: Group discussions, teamwork, and peer interaction to foster a collaborative learning environment.
Regular Assessments: Periodic quizzes and assessments to evaluate progress and identify areas for improvement.
FAQs about PySpark Certification Course
1. What is PySpark?
PySpark is a Python library for Apache Spark, providing a seamless interface to integrate Python with the Spark framework for efficient big data processing.
2. Why should I opt for a PySpark certification course?
A PySpark certification course equips you with the skills needed to analyze large-scale data efficiently, making you highly valuable in the data analytics job market.
3. Are there any prerequisites for enrolling in a PySpark certification course?
While prior knowledge of Python can be beneficial, most PySpark certification courses start from the basics, making them accessible to beginners as well.
4. How long does a typical PySpark certification course last?
The duration of a PySpark certification course can vary, but it typically ranges from a few weeks to a few months, depending on the depth of the curriculum.
5. Can I access course materials and resources after completing the course?
Yes, many institutions provide access to course materials, resources, and alumni networks even after completing the course to support continued learning and networking.
6. Will I receive a certificate upon course completion?
Yes, upon successful completion of the PySpark certification course, you will be awarded a certificate, validating your proficiency in PySpark.
7. Is PySpark suitable for individuals without a background in data science?
Absolutely! PySpark courses are designed to accommodate individuals from diverse backgrounds, providing a structured learning path for beginners.
8. What career opportunities can a PySpark certification unlock?
A PySpark certification can open doors to various career opportunities, including data analyst, data engineer, machine learning engineer, and more, in industries dealing with big data.
In conclusion, mastering PySpark through a well-structured certification course can significantly enhance your career prospects in the ever-evolving field of big data analytics. Invest in your education, embrace the power of PySpark, and unlock a world of possibilities in the realm of data processing and analysis.

1 note
·
View note
Text
Data Engineering Fundamentals Every Data Engineer Should Know

Data engineering is essential for modern data-driven organizations. A data engineer’s expertise in collecting, transforming, and preparing data is fundamental to extracting meaningful insights and driving strategic initiatives. Data engineering is a field that is constantly evolving, and it is important to stay up-to-date on the latest trends and technologies. In this article, we delve into the foundational concepts that every data engineer should be well-versed in.
1. Data Pipeline Architecture
At the heart of data engineering lies the design and construction of data pipelines. These pipelines serve as pathways for data to flow from various sources to destinations, often involving extraction, transformation, and loading (ETL) processes. Understanding different pipeline architectures, such as batch processing and real-time streaming, is essential for efficiently handling data at scale.
2. Big Data Foundations: SQL and NoSQL Databases
Data engineers should be familiar with both relational and NoSQL databases. Relational databases offer structured storage and support for complex queries, while NoSQL databases provide flexibility for unstructured or semi-structured data. Mastering database design, indexing, and optimization techniques is crucial for managing data effectively.
3. Python for Data Engineering
Python’s extensive libraries and packages make it a powerful tool for data engineering tasks. From data manipulation and transformation to connecting with APIs and databases, Python’s flexibility allows data engineers to perform a variety of tasks using a single programming language. Python is a powerful language for data engineering, with capabilities for automation, integration, exploration, visualization, API interaction, error handling, and community support.
4. Data Transformation
Raw data often requires cleaning and transformation to be useful. Data engineers should be skilled in data transformation techniques, including data normalization, aggregation, and enrichment. Proficiency in tools like Apache Spark or SQL for data manipulation is a fundamental aspect of this process.
5. Cloud Services: AWS Certified Data Analytics Specialty
As organizations shift towards cloud computing, data engineers must be well-versed in cloud services. Familiarity with platforms like AWS, Google Cloud, or Azure is essential for building scalable and cost-effective data solutions. Understanding how to set up and manage cloud-based data storage, computing, and processing is a key skill.
Become an AWS data analytics expert with Datavalley’s comprehensive course. Learn data collection, storage, processing, and pipelines with Amazon S3, Redshift, AWS Glue, QuickSight, SageMaker, and Kinesis. Prepare for the certification exam and unlock new career possibilities.
6. Data Modeling
Data modeling involves designing the structure of databases to ensure data integrity and efficient querying. Data engineers should be comfortable with conceptual, logical, and physical data modeling techniques. Properly designed data models facilitate optimized storage and retrieval of information.
7. Distributed Data Processing
In the age of big data, distributed data processing frameworks like Hadoop and Spark are essential tools for data engineers. Learning how to use these frameworks allows you to process large datasets in parallel efficiently. Learn distributed data processing with Big Data Hadoop, HDFS, Apache Spark, PySpark, and Hive. Gain hands-on experience with the Hadoop ecosystem to tackle big data challenges.
8. Data Quality and Validation
Ensuring data quality is paramount. Data engineers should know how to implement data validation checks to identify and rectify anomalies or errors. Proficiency in data profiling, outlier detection, and data cleansing techniques contributes to accurate and reliable analysis.
9. Version Control and Collaboration
Data engineering often involves collaboration within teams. Understanding version control systems like Git ensures efficient collaboration, code management, and tracking of changes. This is crucial for maintaining the integrity of data engineering projects.
10. Data Lake Table Format Framework
Data lakes are becoming increasingly prevalent. Exploring the table format framework within data lakes allows data engineers to efficiently organize and manage vast amounts of diverse data. Learn about Delta Lake and Hudi for data lake management. Delta Lake provides data consistency, reliability, and versioning. Hudi offers stream processing and efficient data ingestion. Work on real-world projects to elevate your expertise.
11. Scalability and Performance
Scalability is a core consideration in data engineering. Data engineers should comprehend techniques for horizontal and vertical scaling to handle growing data volumes. Optimizing query performance and database indexing contribute to efficient data processing.
12. Security and Compliance
Data security and compliance are paramount in data engineering. Data engineers should be well-versed in encryption, access control, and compliance regulations such as GDPR. Implementing robust security measures safeguards sensitive data.
Conclusion
In conclusion, every data engineer should have a thorough understanding of these fundamental concepts. Data professionals need expertise in specialized topics and DevOps principles to navigate data complexities, lead organizations to data-driven excellence, and remain at the forefront of innovation.
Data engineers can utilize their skills in creating efficient data pipelines and ensuring data quality and security to unlock the full potential of data for insights that drive organizational growth. Data engineers need to master essential skills to stay ahead of the data landscape and drive transformative insights.
Become a Data Engineer
Datavalley’s Big Data Engineer Masters Program helps you develop the skills necessary to become an expert in data engineering. It offers comprehensive knowledge in Big Data, SQL, NoSQL, Linux, and Git. The program provides hands-on training in big data processing with Hadoop, Spark, and AWS tools like Lambda, EMR, Kinesis, Athena, Glue, and Redshift. You will gain in-depth knowledge of data lake storage frameworks like Delta Lake and Hudi. Work on individual projects designed to equip the learners with hands-on experience. By the end of this course, you will have the skills and knowledge necessary to design and implement scalable data engineering pipelines on AWS using a range of services and tools.
0 notes
Text

Best Pyspark Certification Training..?
Are you looking for the best Pyspark certification training? Look no further than Lorcam Securities! Our comprehensive training program will ensure that you become a PySpark master – Lorcam has some of the best experts in the field, so you can rest assured that you’re in the right hands. Plus, our program includes unlimited access to study materials and questions, so you can review and practice anytime! Make your dreams a reality today and sign up with Lorcam Securities now.
0 notes
Text
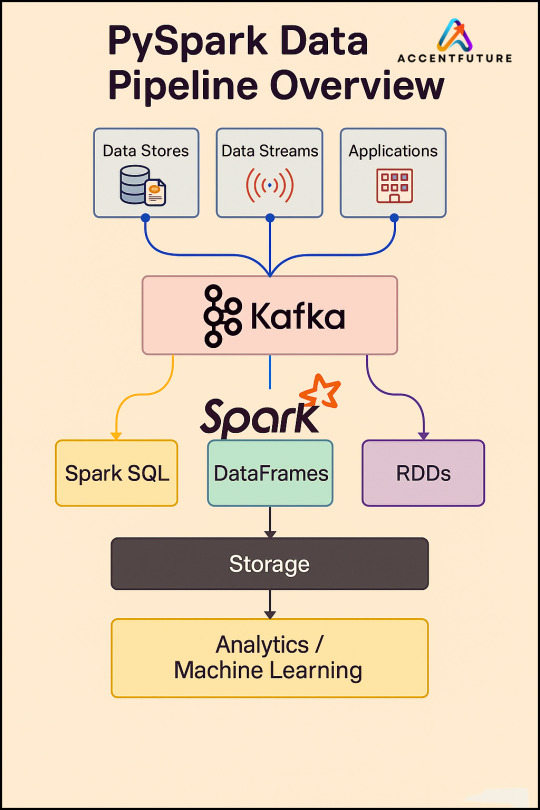
PySpark SQL: Introduction & Basic Queries
Introduction
In today’s data-driven world, the volume and variety of data have exploded. Traditional tools often struggle to process and analyze massive datasets efficiently. That’s where Apache Spark comes into the picture — a lightning-fast, unified analytics engine for big data processing.
For Python developers, PySpark — the Python API for Apache Spark — offers an intuitive way to work with Spark. Among its powerful modules, PySpark SQL stands out. It enables you to query structured data using SQL syntax or DataFrame operations. This hybrid capability makes it easy to blend the power of Spark with the familiarity of SQL.
In this blog, we'll explore what PySpark SQL is, why it’s so useful, how to set it up, and cover the most essential SQL queries with examples — perfect for beginners diving into big data with Python.

Agenda
Here's what we'll cover:
What is PySpark SQL?
Why should you use PySpark SQL?
Installing and setting up PySpark
Basic SQL queries in PySpark
Best practices for working efficiently
Final thoughts
What is PySpark SQL?
PySpark SQL is a module of Apache Spark that enables querying structured data using SQL commands or a more programmatic DataFrame API. It offers:
Support for SQL-style queries on large datasets.
A seamless bridge between relational logic and Python.
Optimizations using the Catalyst query optimizer and Tungsten execution engine for efficient computation.
In simple terms, PySpark SQL lets you use SQL to analyze big data at scale — without needing traditional database systems.
Why Use PySpark SQL?
Here are a few compelling reasons to use PySpark SQL:
Scalability: It can handle terabytes of data spread across clusters.
Ease of use: Combines the simplicity of SQL with the flexibility of Python.
Performance: Optimized query execution ensures fast performance.
Interoperability: Works with various data sources — including Hive, JSON, Parquet, and CSV.
Integration: Supports seamless integration with DataFrames and MLlib for machine learning.
Whether you're building dashboards, ETL pipelines, or machine learning workflows — PySpark SQL is a reliable choice.
Setting Up PySpark
Let’s quickly set up a local PySpark environment.
1. Install PySpark:
pip install pyspark
2. Start a Spark session:
from pyspark.sql import SparkSession spark = SparkSession.builder \ .appName("PySparkSQLExample") \ .getOrCreate()
3. Create a DataFrame:
data = [("Alice", 25), ("Bob", 30), ("Clara", 35)] columns = ["Name", "Age"] df = spark.createDataFrame(data, columns) df.show()
4. Create a temporary view to run SQL queries:
df.createOrReplaceTempView("people")
Now you're ready to run SQL queries directly!
Basic PySpark SQL Queries
Let’s look at the most commonly used SQL queries in PySpark.
1. SELECT Query
spark.sql("SELECT * FROM people").show()
Returns all rows from the people table.
2. WHERE Clause (Filtering Rows)
spark.sql("SELECT * FROM people WHERE Age > 30").show()
Filters rows where Age is greater than 30.
3. Adding a Derived Column
spark.sql("SELECT Name, Age, Age + 5 AS AgeInFiveYears FROM people").show()
Adds a new column AgeInFiveYears by adding 5 to the current age.
4. GROUP BY and Aggregation
Let’s update the data with multiple entries for each name:
data2 = [("Alice", 25), ("Bob", 30), ("Alice", 28), ("Bob", 35), ("Clara", 35)] df2 = spark.createDataFrame(data2, columns) df2.createOrReplaceTempView("people")
Now apply aggregation:
spark.sql(""" SELECT Name, COUNT(*) AS Count, AVG(Age) AS AvgAge FROM people GROUP BY Name """).show()
This groups records by Name and calculates the number of records and average age.
5. JOIN Between Two Tables
Let’s create another table:
jobs_data = [("Alice", "Engineer"), ("Bob", "Designer"), ("Clara", "Manager")] df_jobs = spark.createDataFrame(jobs_data, ["Name", "Job"]) df_jobs.createOrReplaceTempView("jobs")
Now perform an inner join:
spark.sql(""" SELECT p.Name, p.Age, j.Job FROM people p JOIN jobs j ON p.Name = j.Name """).show()
This joins the people and jobs tables on the Name column.
Tips for Working Efficiently with PySpark SQL
Use LIMIT for testing: Avoid loading millions of rows in development.
Cache wisely: Use .cache() when a DataFrame is reused multiple times.
Check performance: Use .explain() to view the query execution plan.
Mix APIs: Combine SQL queries and DataFrame methods for flexibility.
Conclusion
PySpark SQL makes big data analysis in Python much more accessible. By combining the readability of SQL with the power of Spark, it allows developers and analysts to process massive datasets using simple, familiar syntax.
This blog covered the foundational aspects: setting up PySpark, writing basic SQL queries, performing joins and aggregations, and a few best practices to optimize your workflow.
If you're just starting out, keep experimenting with different queries, and try loading real-world datasets in formats like CSV or JSON. Mastering PySpark SQL can unlock a whole new level of data engineering and analysis at scale.
PySpark Training by AccentFuture
At AccentFuture, we offer customizable online training programs designed to help you gain practical, job-ready skills in the most in-demand technologies. Our PySpark Online Training will teach you everything you need to know, with hands-on training and real-world projects to help you excel in your career.
What we offer:
Hands-on training with real-world projects and 100+ use cases
Live sessions led by industry professionals
Certification preparation and career guidance
🚀 Enroll Now: https://www.accentfuture.com/enquiry-form/
📞 Call Us: +91–9640001789
📧 Email Us: [email protected]
🌐 Visit Us: AccentFuture
1 note
·
View note
Text
Mastering Big Data Tools: Scholarnest's Databricks Cloud Training

In the ever-evolving landscape of data engineering, mastering the right tools is paramount for professionals seeking to stay ahead. Scholarnest, a leading edtech platform, offers comprehensive Databricks Cloud training designed to empower individuals with the skills needed to navigate the complexities of big data. Let's explore how this training program, rich in keywords such as data engineering, Databricks, and PySpark, sets the stage for a transformative learning journey.
Diving into Data Engineering Mastery:
Data Engineering Course and Certification:
Scholarnest's Databricks Cloud training is structured as a comprehensive data engineering course. The curriculum is curated to cover the breadth and depth of data engineering concepts, ensuring participants gain a robust understanding of the field. Upon completion, learners receive a coveted data engineer certification, validating their expertise in handling big data challenges.
Databricks Data Engineer Certification:
The program places a special emphasis on Databricks, a leading big data analytics platform. Participants have the opportunity to earn the Databricks Data Engineer Certification, a recognition that holds substantial value in the industry. This certification signifies proficiency in leveraging Databricks for efficient data processing, analytics, and machine learning.
PySpark Excellence Unleashed:
Best PySpark Course Online:
A highlight of Scholarnest's offering is its distinction as the best PySpark course online. PySpark, the Python library for Apache Spark, is a pivotal tool in the data engineering arsenal. The course delves into PySpark's intricacies, enabling participants to harness its capabilities for data manipulation, analysis, and processing at scale.
PySpark Training Course:
The PySpark training course is thoughtfully crafted to cater to various skill levels, including beginners and those looking for a comprehensive, full-course experience. The hands-on nature of the training ensures that participants not only grasp theoretical concepts but also gain practical proficiency in PySpark.
Azure Databricks Learning for Real-World Applications:
Azure Databricks Learning:
Recognizing the industry's shift towards cloud-based solutions, Scholarnest's program includes Azure Databricks learning. This module equips participants with the skills to leverage Databricks in the Azure cloud environment, aligning their knowledge with contemporary data engineering practices.
Best Databricks Courses:
Scholarnest stands out for offering one of the best Databricks courses available. The curriculum is designed to cover the entire spectrum of Databricks functionalities, from data exploration and visualization to advanced analytics and machine learning.
Learning Beyond Limits:
Self-Paced Training and Certification:
The flexibility of self-paced training is a cornerstone of Scholarnest's approach. Participants can learn at their own speed, ensuring a thorough understanding of each concept before progressing. The self-paced model is complemented by comprehensive certification, validating the mastery of Databricks and related tools.
Machine Learning with PySpark:
Machine learning is seamlessly integrated into the program, providing participants with insights into leveraging PySpark for machine learning applications. This inclusion reflects the program's commitment to preparing professionals for the holistic demands of contemporary data engineering roles.
Conclusion:
Scholarnest's Databricks Cloud training transcends traditional learning models. By combining in-depth coverage of data engineering principles, hands-on PySpark training, and Azure Databricks learning, this program equips participants with the knowledge and skills needed to excel in the dynamic field of big data. As the industry continues to evolve, Scholarnest remains at the forefront, ensuring that professionals are not just keeping pace but leading the way in data engineering excellence.
#data engineering#data engineering course#data engineering certification#databricks data engineer certification#pyspark course#databricks courses online#best pyspark course online#best pyspark course#pyspark online course#databricks learning#data engineering courses in bangalore#data engineering courses in india#azure databricks learning#pyspark training course#big data
1 note
·
View note
Link
3 notes
·
View notes
Note
Hi, can you please give me an advise? I'm a marketing student, and I want to work with big data and business intelligence. Do you think knowing python and R are enough? Thank you!
Hello!
I'm not terribly familiar with the whole analytics realm, but I can share what I know.
For business analytics, I know SAS is a popular programming language. It's a little pricey, but you can get university edition for free and try it out. Some universities even offer SAS certification in their business/marketing departments. R and Python are always safe bets. Another name that's been coming up is Tableau, but I'm not sure how prominent it is.
For big data, I might recommend python. There's a great library (based on Hadoop) called PySpark that is geared towards big data. I've worked a little bit with it and was able to churn through 200 terabytes of cloud data in about six minutes. R and SAS can handle big data as well, I just have no experience with those languages.
I hope this helps and I hope your studies go well!
4 notes
·
View notes